| Intent Detection and Slot Filling(更新中。。。) | 您所在的位置:网站首页 › intent intention › Intent Detection and Slot Filling(更新中。。。) |
Intent Detection and Slot Filling(更新中。。。)
 在对话系统的NLU中,意图识别(Intent Detection,简写为ID)和槽位填充(Slot Filling,简写为SF)是两个重要的子任务。其中,意图识别可以看做是NLP中的一个分类任务,而槽位填充可以看做是一个序列标注任务,在早期的系统中,通常的做法是将两者拆分成两个独立的子任务。但这种做法跟人类的语言理解方式是不一致的,事实上我们在实践中发现,两者很多时候是具有较强相关性的,比如下边的例子: 1.我要听[北京天安门, song] -- Intent:播放歌曲2.帮我叫个车,到[北京天安门, location] -- Inent:打车3.播放[忘情水, song] -- Intent:播放歌曲4.播放[复仇者联盟, movie] -- Intent:播放视频1和2中,可以看到同样是“北京天安门”,由于意图的不同,该实体具备完全不同的槽位类型。3和4中,由于槽位类型的不同,导致了最终意图的不同,这往往意味着,在对话系统中的后继流程中将展现出完全不同的行为-----打开网易音乐播放歌曲 or 打开爱奇艺播放电影。 随着对话系统的热度逐渐上升,研究的重点也逐渐倾向于将两个任务进行联合,以充分利用意图和槽位中的语义关联。那么,问题来了,我们该如何进行联合呢?从目前的趋势来看,大体上有两大类方法: 多任务学习:按Multi-Task Learning的套路,在学习时最终的loss等于两个任务的loss的weight sum,两者在模型架构上仍然完全独立,或者仅共享特征编码器。交互式模型:将模型中Slot和Intent的隐层表示进行交互,引入更强的归纳偏置,最近的研究显示,这种方法的联合NLU准确率更高。接下来,我们将对这两类方法涉及到的部分文献进行分析,为大家的研究提供参考。 常用公开数据集1.ATIS 数据集信息:航空旅行领域的语料,上个世纪发布的数据,是对话领域常用的数据集。 该数据集规模很小,训练集4400+,测试集800+,槽位意图识别难度不大,目前处于被刷爆的程度,intent detection和slot filling任务的F值都已经在95+以上了,唯一可以挑战的是NLU的Acc,也称为Sentence Acc,即输入句子的意图、槽位同时正确才算该样本预测正确。目前的SOTA为Bert,具体可上paper-with-code网站搜索 当前的SOTA: 2.SNIPS 中文数据集: CQUD TODO。。。 多任务学习A Joint Model of Intent Determination and Slot Filling for Spoken Language Understanding 现在来看,这篇文章没什么特别,两个任务共享编码器-----Slot Filling任务取每个时刻的输出 h_t 作为任务层输入特征,而Intent Detection任务取 h^u=maxpooling(h_1,h_2,...,h_T) 做为任务层特征。另外在输入特征有一些改进:输入x取上下文窗口(word级别、Namely Entity级别等),目前这些都属于常规操作了~~  最后训练的损失,就是两个任务损失的weight sum:  loss for Intent detection loss for Intent detection loss for slot filling loss for slot fillingSlot Filling任务的loss中,有个 \Delta(l^s,\hat{l^s)} 比较有意思,它的计算方法如下:  最后,总体的loss,其中, \alpha 是超参数,调节两个任务的权重:  total loss, alpha is a hyperparameter total loss, alpha is a hyperparameter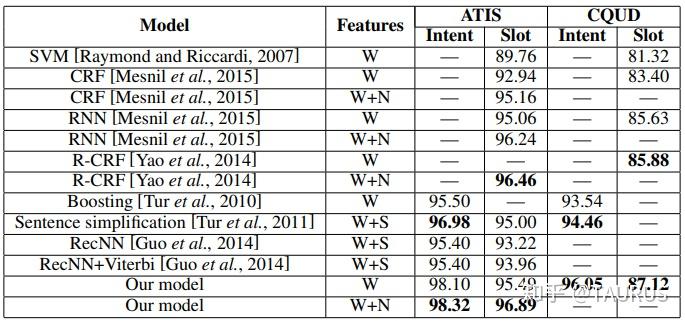  ATIS: equal(a=1.6),ID oriented(a=1.6),SF oriented(a=1.8); CQUD:equal(a=1.5),ID oriented(a=2.0),SF oriented(a=1.8) ATIS: equal(a=1.6),ID oriented(a=1.6),SF oriented(a=1.8); CQUD:equal(a=1.5),ID oriented(a=2.0),SF oriented(a=1.8)这篇文章最后只说了联合模型能够提高意图和槽位的准确率,但是实验中并没有给出最终两者联合的NLU准确率 Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling 本文提出了,Attention-Based RNN模型,主要目的在于保留Attention Encoder-Decoder架构对齐信息的建模能力,同时减少计算量(没有单独的Decoder层)。文中先说了Encoder-Decoder模型的套路: 首先计算出decoder输出对Encoder中每个时刻hidden状态的Attention系数:  然后通过加权和,求出每个时刻的context向量:  最后将context向量输入到解码器当前的时间步中,计算模型的输出:  其中, y_{i-1} 是上一时刻模型的decoder的输出标签,实际操作时需要经过一层Embedding处理,转换成向量输入到decoder中。 h_i 代表当前时刻的隐层状态, s_{i-1} 代表上一时刻的Decoder隐层状态(注意不是输出标签)。作者认为,通过注意计算出来的 c_i 蕴含了槽位标签和输入间的对齐信息,有助于提高槽位预测的能力。文中提到的aligned inputs(后边称对齐信息)指上一时刻的输出标签y_{i-1} 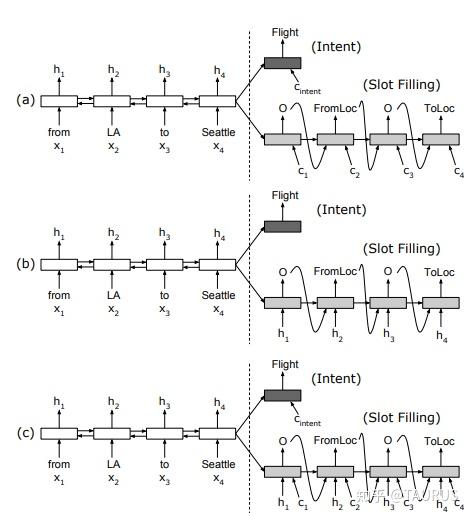 with no aligned inputs. (b) with aligned inputs.(c) with aligned inputs and attention with no aligned inputs. (b) with aligned inputs.(c) with aligned inputs and attention可以看到,Encoder-Decoder的方式,在编码和解码阶段都有RNN结构,这将使得模型性能低下,因为RNN本身就是串行计算,再有两个就更慢了。于是,本文提出了Attention-Based RNN(感觉也不算什么创新。。。),操作如下: 去掉Decoder模块,直接用Encoder的输出进行预测将对齐信息直接加到了BiLSTM的后边一层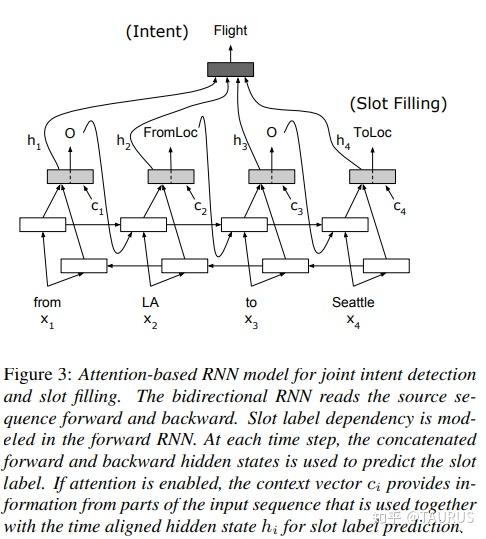 实验结果:  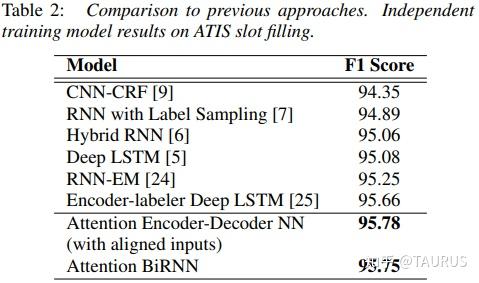    A Bi-model based RNN Semantic Frame Parsing Model for Intent Detection and Slot Filling 这篇文章是Samsung Research America发的,主要特点在于使用了两个BiRNN分别对intent和slot进行encoding,并且,两个编码器的特征相互共享,以增加语义关联。最后训练时采用异步训练  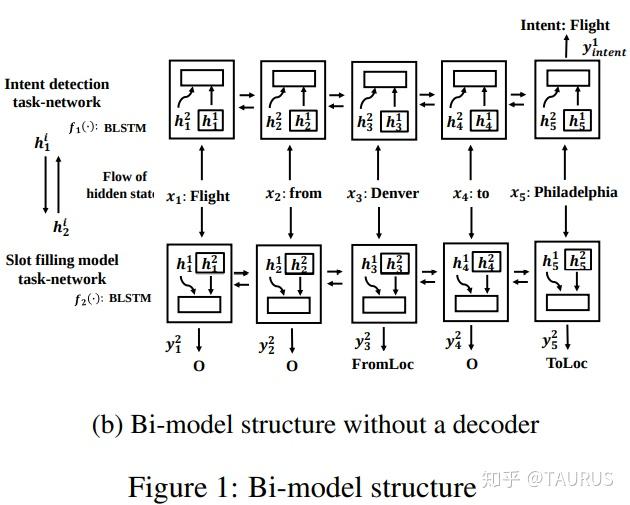 实验结果,在ATIS数据集上结果很好,Intent Detection的效果甚至超过了Bert,这不禁让人怀疑结果的可复现性,由于作者没有提供源码,这个结果的真实性难以验证。 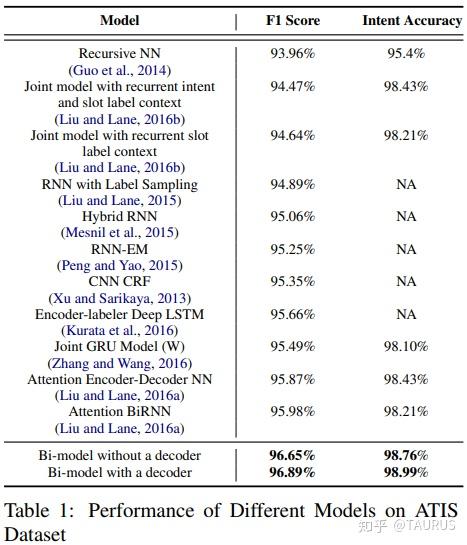  Joint semantic utterance classification and slot filling with recursive neural networks BERT for Joint Intent Classification and Slot Filling 这个没有什么好说的,本质上就是把原来的Encoder换成了Bert,效果当然是杠杠的,目前的SOTA。从实验结果,我们可以看到一个有趣的现象,在为输出增加CRF层后,效果变化并不是很明显(一个数据集下降,一个上升,差距在0.5以内)。可见,预训练模型强大的特征抽取能力,本身已经足够对上下文的关联进行建模,标签序列的依赖并不能带来更多的信息。另外,这篇文章中提到了其原因可能是基于预训练模型训练时Learning rate较低,CRF层本身的参数没有充分学习导致。但文中也指出,即使调高学习率,保证学习到合理的转移矩阵,最终结果相比直接用softmax也不会有太大变化,再次验证了后bert时代的真理----简单的就是最好的。  模型的Sentence Acc也非常的高,达到了88+ 模型的Sentence Acc也非常的高,达到了88+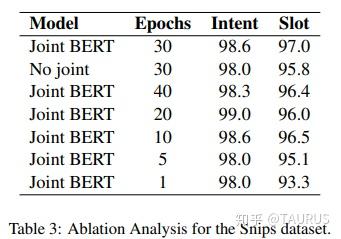 Multi-lingual Intent Detection and Slot Filling in a Joint BERT-based Model 交互式模型Slot-Gated Modeling for Joint Slot Filling and Intent Prediction 在本文中,作者创新性的提出了Slot-Gate 机制,增大了两个任务间的交互程度。本文是Slot-Gate机制的第一篇文章,后继的文章多有借鉴。 模型概要:  模型结构图模型结构 模型结构图模型结构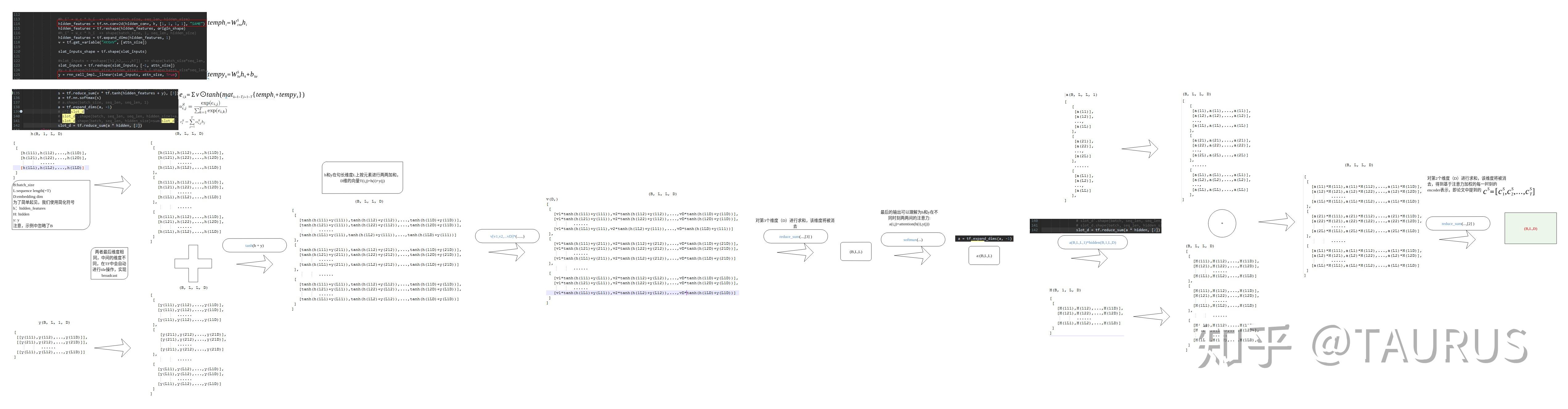 Attention核心代码分析 Attention核心代码分析 slot gate结构图,在每一个时间步i,都将输出一个标量g slot gate结构图,在每一个时间步i,都将输出一个标量g训练的时候,采用传统套路,将两个任务的loss相加,进行联合优化:   注意:最后的等式取log后就可以转变成loss(intent)+loss(slot)的形式 注意:最后的等式取log后就可以转变成loss(intent)+loss(slot)的形式小结: 对话中的NLU任务通常包含Intent Detection和Slot Filling两个子任务,这两个任务之间往往是相互关联的,gate mechanism 对slot filling添加intent的信息, 单看Slot或Intent的效果不是很突出,但是整体NLU的效果提升有近2%,可以看出这种机制确实更好的modeling了两个任务间的相关性。而且提供源代码(这个要点赞)可见作者对结果还是很有信心的。但文章有暴露出了一个缺陷:对于Slot Filling,作者考虑了Intent的信息,但对于Intent Detection任务,模型中并未考虑融合Slot的信息,这为后继优化提供了一个缺口(具体可以参看下一片论文的分析) 实验结果:  A novel bi-directional interrelated model for joint intent detection and slot filling 本文来自北京交通大学。在上文的基础上,进一步加强了两个任务间的交互: 在Intent Detection任务中引入了slot的信息通过迭代机制,增强交互模型结构如下: 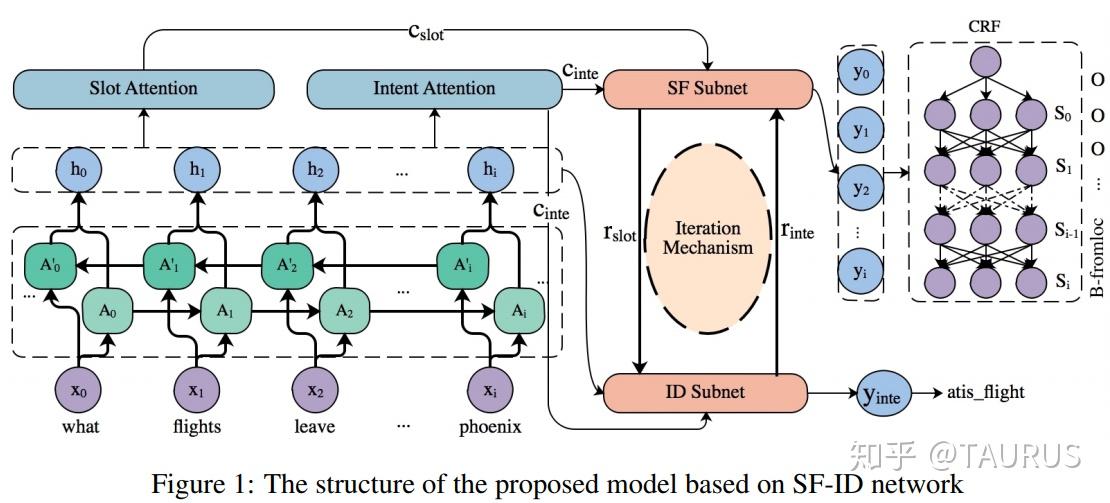 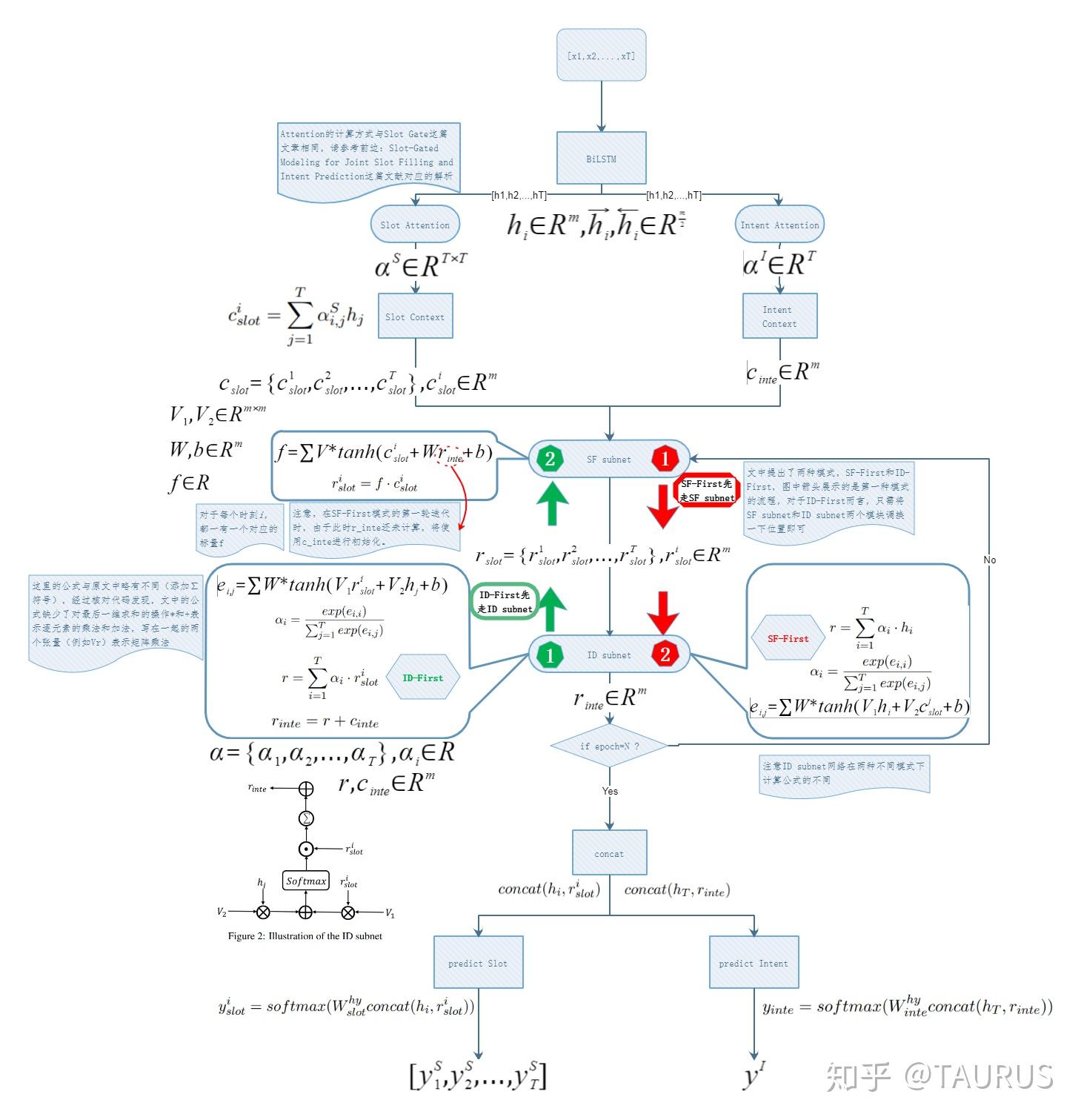 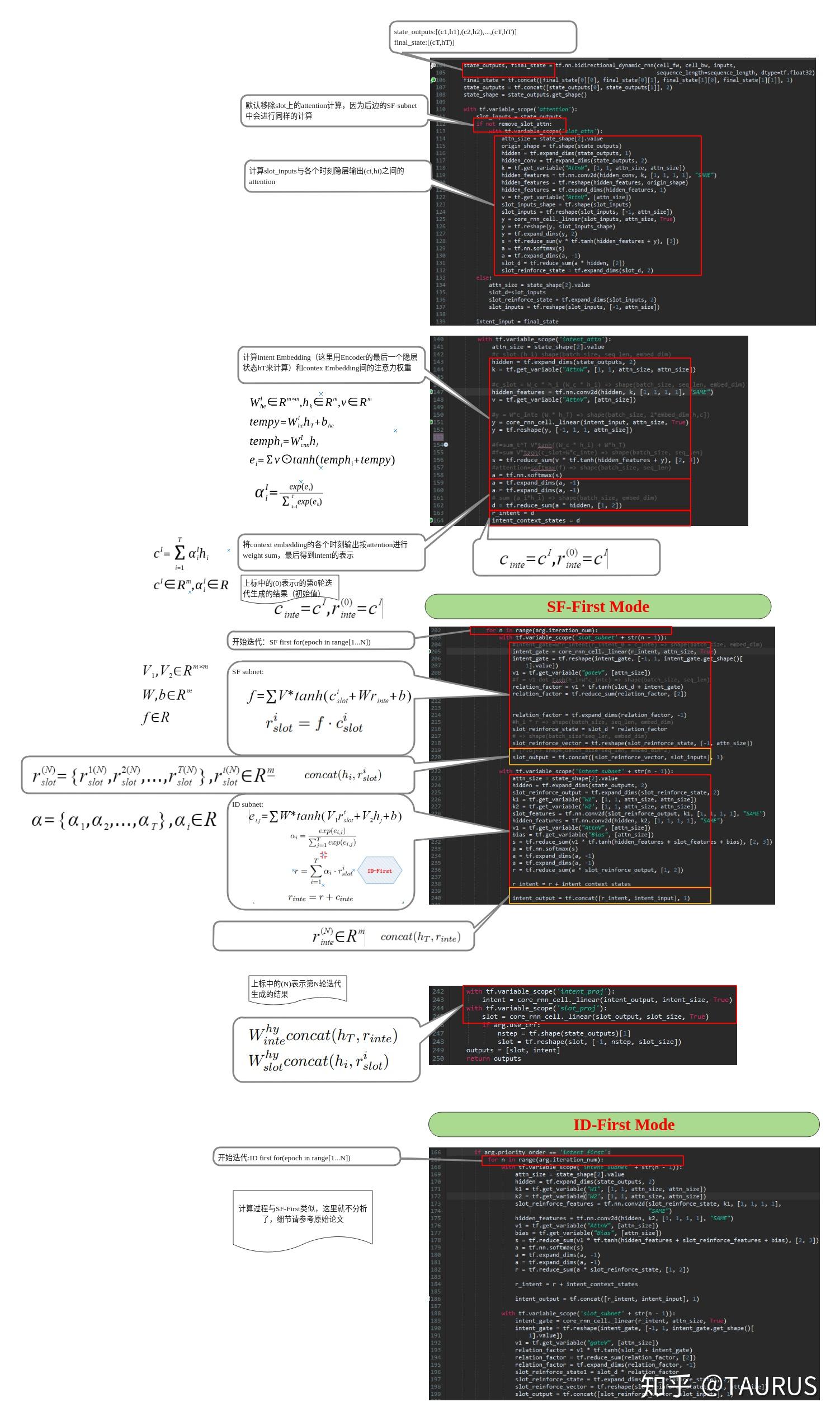 代码分析 代码分析小结: 这篇文章作者抓住了Slot-Gated Modeling中为对任务交互信息充分建模的问题,进行了改进,最终结果有了较为明显的提升(2%+),而且同样提供源代码(PS.作者也太懒了,直接用了前文的源代码,在本来就很乱的代码上又加入了自己的实现,让人无力吐槽) 实验结果:  Figure3显示,当ID-SF的交互迭代次数为3的时候效果最好 Figure3显示,当ID-SF的交互迭代次数为3的时候效果最好 训练时的参数配置 训练时的参数配置Joint Slot Filling and Intent Detection via Capsule Neural Networks 本文相当于把Slot-Gate通过Capsule模块来实现。 小结: 本文在ATIS数据集上的Sentence Acc到达了83.4。 实验结果: 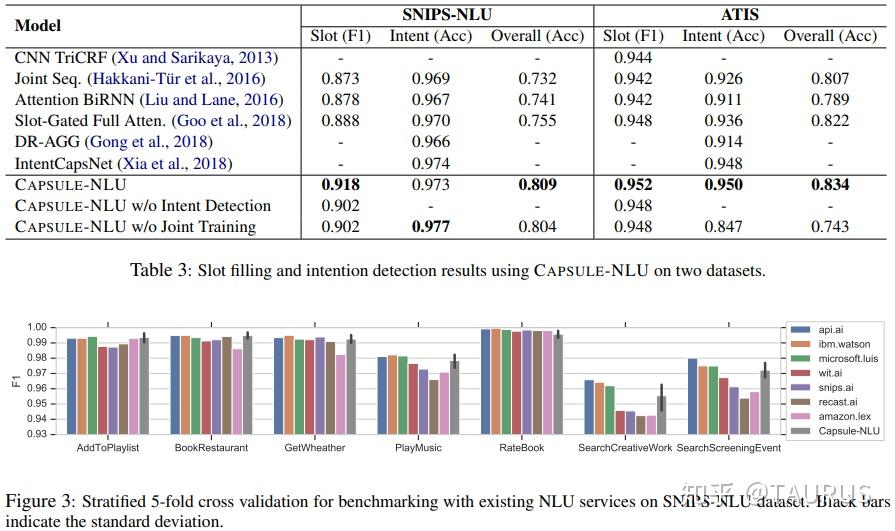   A Self-Attentive Model with Gate Mechanism for Spoken Language Understanding的 本文引入了自注意机制,同时引入了gate机制来modeling两个任务间的交互 本文的所有实验都基于ATIS数据集:  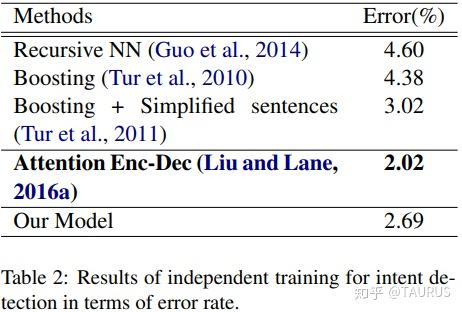  注意,F1值对应slot filling的结果,Error对应Intent Detection的结果 注意,F1值对应slot filling的结果,Error对应Intent Detection的结果最后,文章进行了消融实验,给出了各个重要模块的作用:  多模态: 多模态:对话系统离不开语音交互,在这个小节中,我们专门整理了融合语音信息的文章。 INCORPORATING ASR ERRORS WITH ATTENTION-BASED, JOINTLY TRAINED RNN FOR INTENT DETECTION AND SLOT FILLING 引入纠错任务联合训练,能有效提高slot识别的准确率,缺点是标注成本太高,但可采用qq音乐的纠错字段做半监督标注 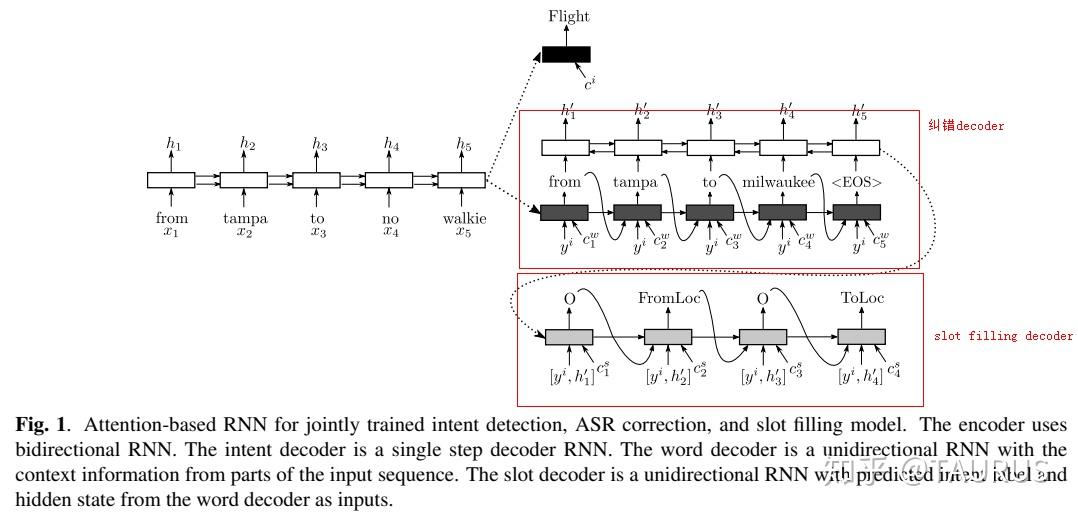  ASR2Intent:end-to-end NLU FROM AUDIO TO SEMANTICS: APPROACHES TO END-TO-END SPOKEN LANGUAGE UNDERSTANDING TOWARDS END-TO-END SPOKEN LANGUAGE UNDERSTANDING 数据增强:Data Augmentation for Spoken Language Understanding via Joint Variational Generation 播放周杰伦的青花瓷 -- 播放{PER,周杰伦}的{SONG,青花瓷} -- play_music 其它: 2014年的一篇文章,引用量比较高,经常作为baseline出现在其它文献中 CONVOLUTIONAL NEURAL NETWORK BASED TRIANGULAR CRF FOR JOINT INTENT DETECTION AND SLOT FILLING; ZSL: Robust Zero-Shot Cross-Domain Slot Filling with Example Values(by google); 后继的改进点: 1.将场景过滤和意图识别融合为一个单模型 2.增加实体名特征 TODO。。。 |
【本文地址】